
近年来,大语言模型(LLMs)在药物设计中的应用取得了很大的进展,但现有的方法往往难以有效整合分子的三维结构。因此,开发一种适用于所有药物设计场景且易于与现有通用大语言模型集成的化学大模型,成为当下急需突破的关键问题。

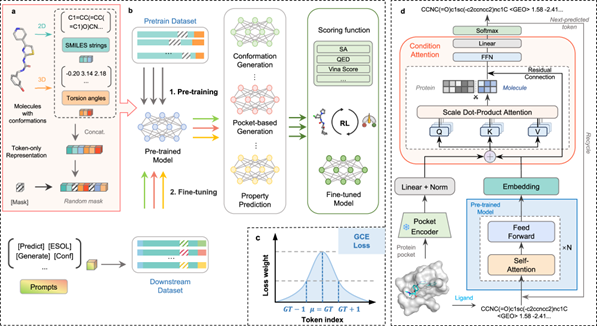
2025年5月13日,浙江大学药学院侯廷军、谢昌谕和康玉团队,在Nature Communications发表题为“Token-Mol 1.0: tokenized drug design with large language models”的论文。该研究提出了一种仅使用词元的三维药物设计模型Token-Mol,其可将二维和三维结构信息以及分子性质编码为离散的词元。Token-Mol基于变换器(Transformer)的解码器架构并采用因果掩蔽训练,引入了一种针对回归任务定制的高斯交叉熵损失函数(GCE),从而在多个下游应用中实现了优异的性能。该模型在多个下游任务上超越了现有方法:分子构象任务中,在两个数据集上生成的表现提高超过10%和20%,同时在性质预测任务方面优于其他仅基于词元的模型达30%。在基于口袋的分子生成中,相比起其他专家模型,Token-Mol分别将药物相似性和合成可及性提高约11%和14%, 在生成速度上相较于基于扩散模型的专家模型快35倍。在模拟真实世界场景的生成中,与强化学习相结合后,模型能一步优化设计分子的亲和力和药物相似性。
浙江大学药学院为本论文的第一署名单位,浙江大学王極可博士、博士研究生秦睿和王明阳博士为共同第一作者,侯廷军教授、谢昌谕教授以及康玉副教授为共同通讯作者。

