
现有的mRNA设计模型往往局限于特定区域(如UTR或CDS),难以有效捕捉全长序列的全局特征,且受限于高质量训练数据的匮乏。因此,开发一种能够整合全长序列信息、融合多模态生物特征且适用于多种下游任务的通用mRNA基础模型,成为推动mRNA疗法发展的关键问题。

11月24日,浙江大学药学院侯廷军和谢昌谕团队在Nature Communications发表题为“mRNABERT: advancing mRNA sequence design with a universal language model and comprehensive dataset”的论文。该研究提出了首个基于大规模高质量数据(1800万条序列)预训练的通用mRNA设计模型mRNABERT。该模型创新性地采用了双重词元化策略,将非翻译区的核苷酸和编码区的密码子分别编码,并引入跨模态对比学习框架以融合蛋白质序列的语义信息。mRNABERT基于Transformer架构,利用线性偏差注意力(ALiBi)和Flash Attention技术,有效解决了全长及超长mRNA序列的建模难题。在全面的基准测试中,该模型展现了卓越的性能:在5' UTR核糖体负载预测任务中,其Spearman相关系数最高达到0.962,优于已报到的最优模型;在CDS稳定性和表达预测任务中,全面超越了CodonBERT等基线模型;特别是在全长mRNA性质预测任务中,mRNABERT表现稳健,其R²值比次优模型高出1.6至10.4倍,充分展示了其在mRNA疫苗和药物研发中的巨大应用潜力 。
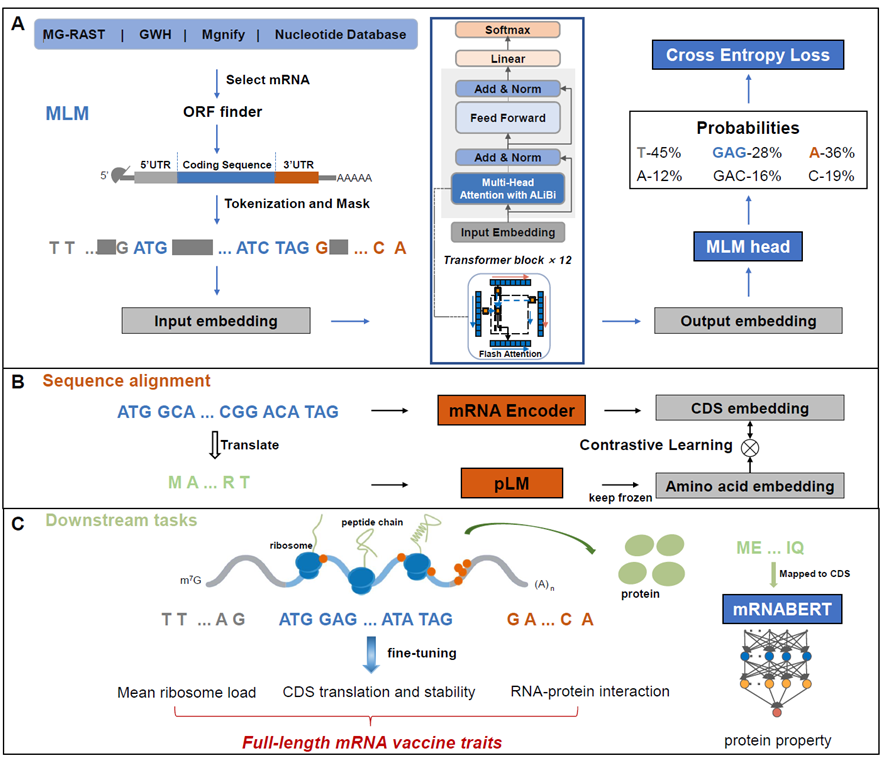
浙江大学药学院为本论文的第一署名单位,浙江大学硕士研究生熊鹰为第一作者,侯廷军教授和谢昌谕教授为共同通讯作者。

